
COVID-19 mortality is associated with test number and government effectiveness

Author(s)
Jiun-Yu WuBiography
Jiun-Yu Wu is an Associate Professor at IED/CTE, National Chiao Tung University, Taiwan. He is a quantitative methodologist specializing in a range of advanced statistical and computational modeling, including Multilevel Structural Equation Modeling (MSEM) and Machine Learning techniques on the analysis of cross-sectional and longitudinal structured/unstructured data. His research interests focus on the cognitive, metacognitive, and behavioral process of how people learn, adapt, and succeed in the technology-enhanced environment.
Academy/University/Organization
National Chiao Tung University-
TAGS
-
Share this article
You are free to share this article under the Attribution 4.0 International license
- HUMANITIES & SOCIAL SCIENCES
- Text & Image
- November 21,2019
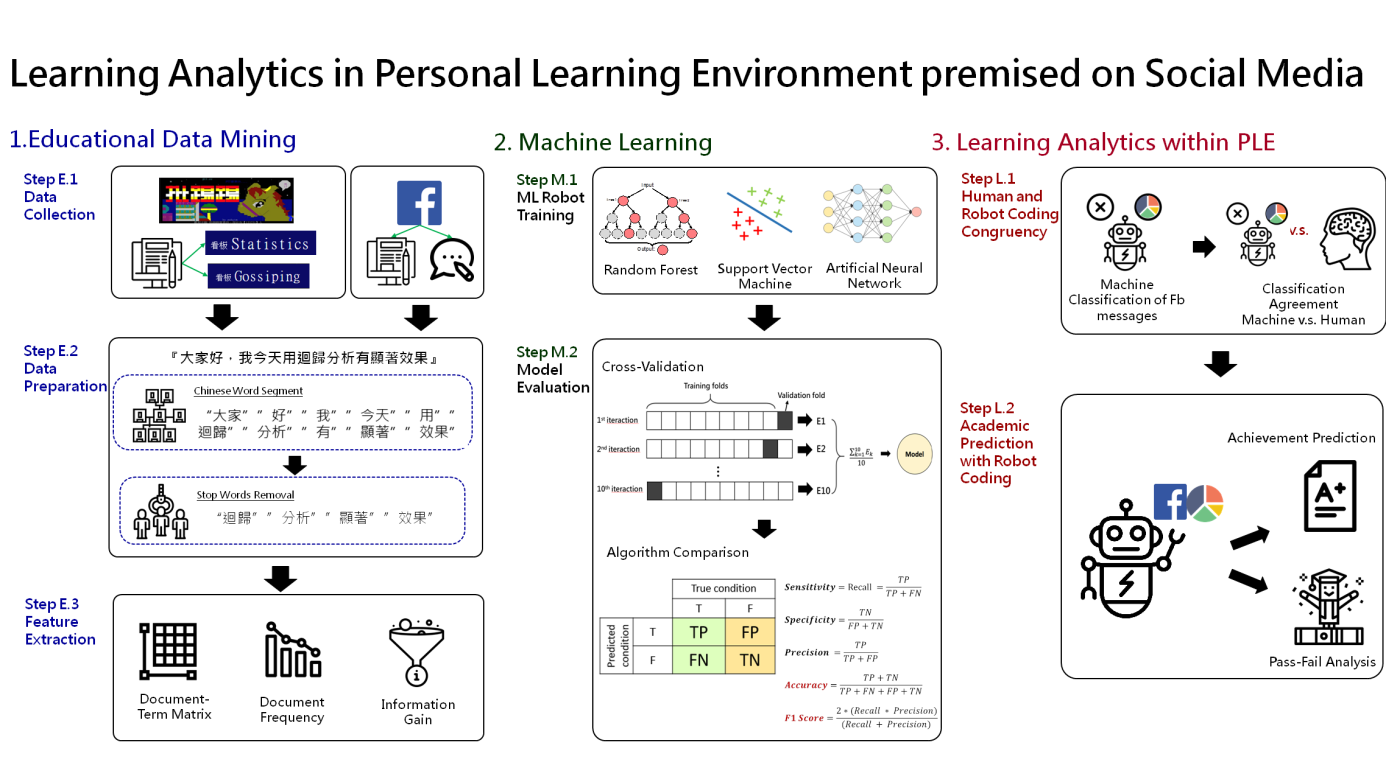
In higher education, the hybrid or blended learning has been widely used to extend the face-to-face class session regardless of the constraints of time and space. The availability of digital footprints brings unparalleled potential to examine people’s learning from different facets and gives rise to interests in the development and use of tools and techniques to support Learning Analytics (LA). In our research, we used Machine Learning (ML), an essential element of Artificial Intelligence (AI), to analyze the vast amount of ill-structured online discussion data and to categorize them into statistics-relevant or statistics-irrelevant messages. Data from the gossip forum and the statistics forum in ptt were obtained to function as the training datasets with labels through web crawling. Next, we tested the classification effectiveness and applied the classification rules on the online Facebook Statistics learning group. The classification effectiveness was then again tested on Facebook messages. Moreover, the classification agreement of the ML algorithm was also evaluated with human coders before the ML classified messages can be used for prediction of student performance. Our findings showed that students with more messages endorsed by the ML algorithms had higher final course grades. Besides, students who failed the course also had significantly fewer messages endorsed by the ML algorithms as statistics relevant than those who passed. The study results suggested that we can harness the power of the networked learning and provide just-in-time support for students to achieve precision education in their Personal Learning Environment through learning analytics.
What’s your impression of learning advanced Statistics? Is it something that the instructor lectures throughout the whole class period, bombarding you with nothing but Greek letters (pun intended)? Or is it something that you have tried really hard to understand but still you cannot get to the point or find available resources to help you? If these descriptions sound familiar to you, then you may be interested in our personal learning environment for statistics learning.
In higher education, hybrid or blended learning has been widely used to extend the face-to-face class session, regardless of the constraints of time and space. Thus, instead of feeling bombarded with all sorts of statistics concepts and terminologies in the classroom, the hybrid learning environment provides students with time to reflect on their thoughts and allows them to ask questions or seek help from their instructor or peer via online discussion. Specifically, learners’ active posting and commenting behaviors on the discussion board can be analyzed to determine their state of learning (e.g., information sharing, needing help, helping others, socializing with fellow students, etc.) and level of participation (e.g., number of posts and comments).
Prior studies usually apply qualitative or content analysis to evaluate the quality of students’ posts and comments on the discussion board, which is however an arduous task and may not be efficiently conducted using human efforts. Nevertheless, the availability of digital data brings unparalleled potential to examine people’s learning from different facets, and gives rise to interest in the development and use of tools and techniques to support Learning Analytics (LA). In our research, we used Machine Learning (ML), an essential element of Artificial Intelligence (AI), to analyze the vast amount of ill-structured online discussion data and to categorize them into statistics-relevant or statistics-irrelevant messages. The ML technique can sort data into a predefined set of generic classes based on the relevance of the texts. Thus, rather than using the strenuous content analysis procedure, ML is capable of performing active learning in categorizing the unstructured discussion posts on the discussion boards.
Specifically, we used the data from large-scale online forums of distinct topics for supervised MLs to categorize discussion messages in the instructor-created Facebook learning group. First, data from the gossip forum and the statistics forum in PTT (the largest terminal-based bulletin board system based in Taiwan) were obtained to function as the training datasets with labels through web crawling. Next, we tested the classification effectiveness and applied the classification rules on the online Facebook Statistics learning group. The classification effectiveness was then again tested on Facebook messages. What’s more, the classification agreement of the ML algorithm was also evaluated with human coders before the ML classified messages could be used for prediction of student performance.
Our findings showed that students with more messages endorsed by the ML algorithms had higher final course grades. Moreover, students who failed the course also had significantly fewer messages endorsed by the ML algorithms as statistics-relevant than those who passed. The study result suggests that students who produced fewer relevant messages may indicate potential risks of course failure and are in need of the instructor’s attention for early remediation. Besides, the study result contributed to the development of ML in education by providing a mechanism through the use of voluminous online informative forums to apply supervised ML for text categorization that facilitate the accuracy, consistency, relevancy, and verifiability of large-scale educational data quality. In terms of the Personal Learning Environment, we hope to create an engaging, flexible, adaptive, and personalized instruction for each student.
The study results further showed that we can use the ML for message classification on the social media for instructors to harness the power of the networked learning and provide just-in-time support for their students to achieve precision education in their Personal Learning Environment.
RELATED


STAY CONNECTED. SUBSCRIBE TO OUR NEWSLETTER.
Add your information below to receive daily updates.