

超高能量密度無陽極鋰電池

AI的應用在網路、雲端以及行動裝置上都已漸趨成熟,企業與政府運用AI技術提升本身效率或衍生創新服務帶來龐大的利益。根據Statista的統計顯示,2020年全球AI相關市場規模估計為225.9億美元,相較前一年度的146.9億美元成長了53.8%,至2025年更將成長至1260.0億美元,可見AI的應用在可見未來將會持續蓬勃發展。
但是在如醫療、商務或是政府資料等牽涉個資的應用領域,基於對個人隱私的防護與法規要求,這些資料無法直接使用,需要對資料的隱私進行適當保護或處理後,才可以讓研究人員進行後續加值分析、研究。
工研院巨資中心資料隱私與平臺技術部研究團隊,為協助資料擁有者合法加值運用資料,近年研發可提供兼顧大數據分析和資料隱私的3種去識別化作法,其中包括常見的K-匿名法、GAN生成資料法,以及從GAN生成資料法衍生出的多機構統計整合法。以下分別說明其基本原理及作法:
1. K匿名法:雖然不是最強的保護方法,卻是最直覺、最容易操作的傳統去識別化方法。利用資料藏匿(Suppression)和資料泛化(Generalization),也就是將資料進行更廣義、更抽象的描述,將確切值隱藏在一個區間達到匿名效果。基本上作法,例如姓名、身份證字號等直接識別資料以加密、置換或刪除處理,而將所謂間接識別資訊(如年齡、地址等)資料隱藏在一個區間。如圖一所示將21歲至30歲的區間都改為30歲,11歲至20歲的區間都改為20歲,將資料顆粒度變粗的情況下,會有更多人符合這些條件組合,提高要從資料中去推斷某特定人的困難度,達到了隱匿效果。
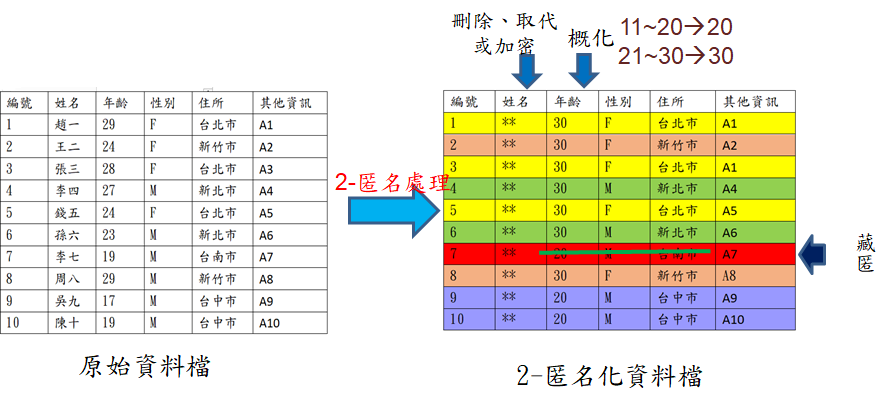
圖一:K(2)-匿名處理示意圖
2. GAN生成資料法:使用所謂的對抗生成網路(GAN)生成器模型產生接近真實資料的合成虛擬資料,來達到匿名且具有分析力的效果。這個作法的原理如圖二所示,以隨機變數輸入GAN生成器(Generator),來產生盡量具有原始資料特性的合成資料,接著用GAN鑑別器(Discriminator)來評斷這些合成資料的擬真度,並回饋每一回合的判斷結果調整生成器,藉此提高合成資料的真實性。這個過程會反覆進行,直到生成器產生的資料成功騙過鑑別器為止。若是有更高強度的隱私保護需求甚至會加入差分隱私,來提高去識別化強度。使用GAN生成的虛擬資料的分析準確度,與原始資料間相比,在經數種機器學習分析方式比較下,兩者的誤差值可在5%以內。
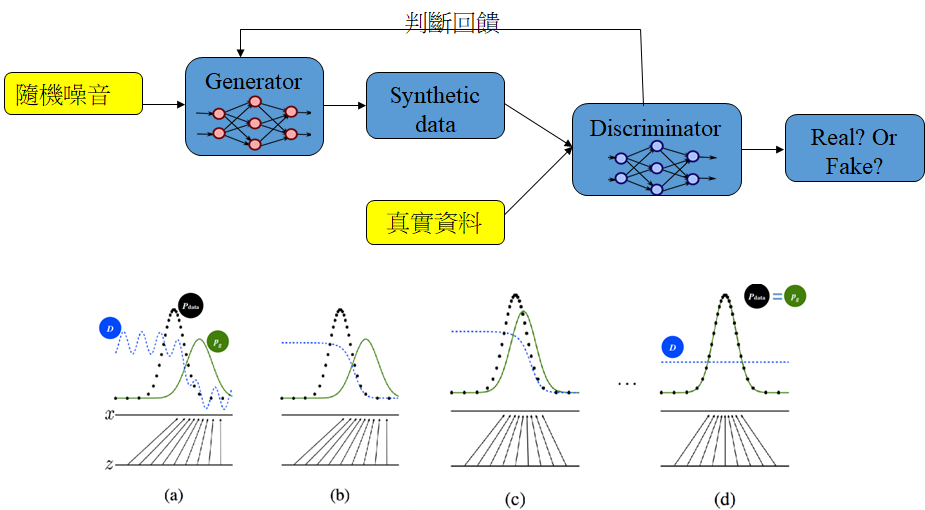
圖二:使用GAN生成合成虛擬資料
3. 用GAN去識別化再融合:整合GAN和傳統統計作法,可用於多機構間的資料去識別化和資料整合分析。其作法先在各機構端以前述的GAN生成資料,再透過橫向整合(Database join)、資料配對(Record linkage)等作法,得到可分析的整體性資料。這個方法整合GAN和傳統統計整合作法,可分為3個步驟,包括在各機構端以GAN生成資料,再以前述統計學橫向整合的技術整合這些資料,最後,匯出這些資料即可得到具有分析力的去識別化資料集。
假設銀行A、電商B分別擁有資料集X、Y和X、Z,其中X是兩家企業是共通客群,而Y和Z是與X相關的資料。為了在兼顧個資隱私的條件下整合兩家資料,雙方得先將手上的資料集X、Y和X、Z以GAN生成近似原始資料的合成資料進行去識別化處理。後續透過橫向整合(Database join)、資料配對(Record linkage)、統計匹配等方法,來整合這些生成資料,完成後再匯出整合的資料集X、Y、Z,來進行後續的分析應用。
目前臺灣已建立個人資料去識別化驗證國家標準CNS29100-2,巨資中心團隊透過相關技術整合並結合外部法律團隊,具備輔導通過去識別化驗證之經驗與能量,期許能基於法人協助產業角色,持續協助國內巨量資料與人工智慧應用發展與創新。
延伸閱讀-科技部(科技大觀園)
相關文章


訂閱電子報以獲得最新資訊
填寫連絡資訊以取得每月發行之電子報