

Science in Our Daily Lives – Material Sciences

Author(s)
Min SunBiography
Dr. Min Sun is an associate professor in the department of Electrical Engineering at National Tsing Hua University (NTHU). His areas of expertise are computer vision, natural language processing, deep learning, reinforcement learning, and AI. He is the latest recipient of the Creative Young Scholar Award from the Foundation for the Advancement of Outstanding Scholarship in Taiwan. Dr. Sun received his Ph.D. in Electrical Engineering: Systems from the University of Michigan and his M.S in Electrical Engineering from Stanford University
Academy/University/Organization
National Tsing Hua UniversitySource
http://arxiv.org/abs/1811.10201v2-
TAGS
-
Share this article
You are free to share this article under the Attribution 4.0 International license
- ENGINEERING & TECHNOLOGIES
- Text & Image
- June 18,2019
In the last decade, breakthroughs in AI have enabled significant performance gains in domains with abundant unstructured data such as images and natural languages. For instance, image recognition has been widely deployed on mobile phones and visual surveillance systems. Natural Language Processing techniques are also widely used in search, Chatbot, and digital marketing. The core technique underlying these breakthroughs is the advance of neural network architecture. However, in the past few years, network architectures have been manually designed by researchers. Designing a significantly better neural network architecture has become harder and heavily relies on experience and expertise. Starting just two years ago, researchers have proposed meta-learning algorithms to automatically design better neural network architectures, which literally enables AI (meta-learning algorithms) to design AI (neural network architecture). The meta-learning algorithm is referred to as Neural Architecture Search (NAS). Among the latest NAS research, we highlight two important studies from our lab. One is the first to optimize for multiple objectives including accuracy, inference time, and model size. The other is the first to search for a distribution of architectures which enables instance-awareness for exploring a better trade-off between inference time and accuracy.
In the last decade, breakthroughs in AI have enabled significant performance gains in domains with abundant unstructured data such as images and natural languages. For instance, image recognition has become widely deployed on mobile phone and visual surveillance systems. Natural Language Processing techniques are also widely used in search, chatbot, and digital marketing. The core technique underlying these breakthroughs is the advance of neural network architecture design. However, in the past few years, new network architectures have been manually designed by researchers. Designing a significantly better neural network architecture has become harder and heavily relies on experience and expertise. Starting just a few years ago, researchers have proposed meta-learning algorithms to automatically design better neural network architectures, which literally enables AI (meta-learning algorithms) to design AI (neural network architecture). The meta-learning algorithm is referred to as Neural Architecture Search (NAS). NAS have achieved impressive performance that is close to or even outperforms the current state-of-the-art designed by domain experts in several challenging tasks, demonstrating strong promises in automating the designs of neural networks.
However, most existing works of NAS only focus on optimizing model accuracy and largely ignore other important factors (or constraints) imposed by underlying hardware and devices. For example, from workstations, mobile devices to embedded systems, each device has different computing resources and environments. Therefore, a state-of-the-art model that achieves excellent accuracy may not be suitable, or even feasible, for being deployed on certain (e.g., battery-driven) computing devices, such as mobile phones.
To this end, we proposed DPP-Net [1], Device-aware Progressive Search for Pareto-optimal Neural Architectures, to extend NAS into multiple objectives, as opposed to the original single objective (i.e., accuracy), to search for device-aware neural architectures. With DPP-Net, factors or constraints imposed by underlying physical devices can be accounted for by being formulated as the corresponding objectives. Therefore, instead of finding the “best” model in terms of accuracy, most of these works embrace the concept of “Pareto optimality” w.r.t. the given objectives, which means none of the objectives can be further improved without worsening some of the other objectives. Experimental results on CIFAR-10 (Table 1) demonstrate that DPP-Net can find various Pareto-optimal networks on three devices: (1) workstation with Titan X GPU, (2) NVIDIA Jetson TX1 embedded system, and (3) mobile phone with ARM Cortex-A53. Most importantly, DPP-Net achieves better performances in both (a) higher accuracy and (b) shorter inference time, compared to the state-of-the-art CondenseNet on three devices. Most importantly, our searched DPP-Net achieves considerably better performance on ImageNet as well (Table 2).
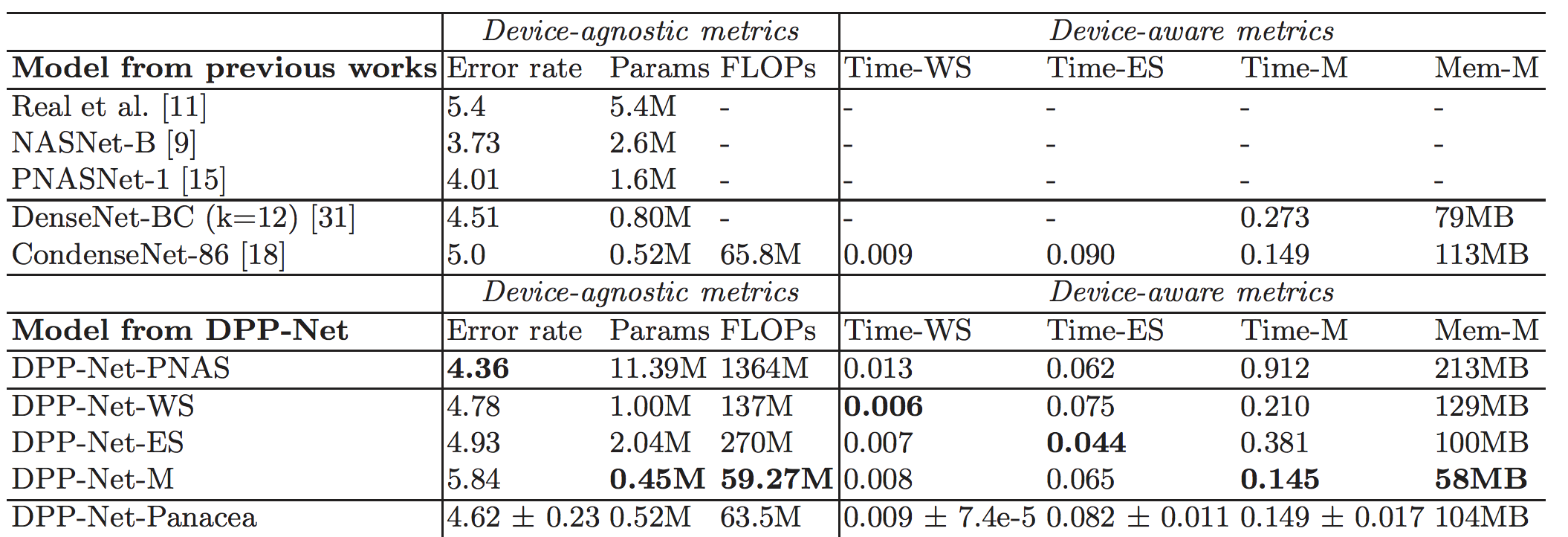
Table 1. Cifar-10 Classification Results. Missing values are the metrics not reported in the original papers. The standard deviation of the metrics of DPP-Net-Panacea are calculated across 10 runs.
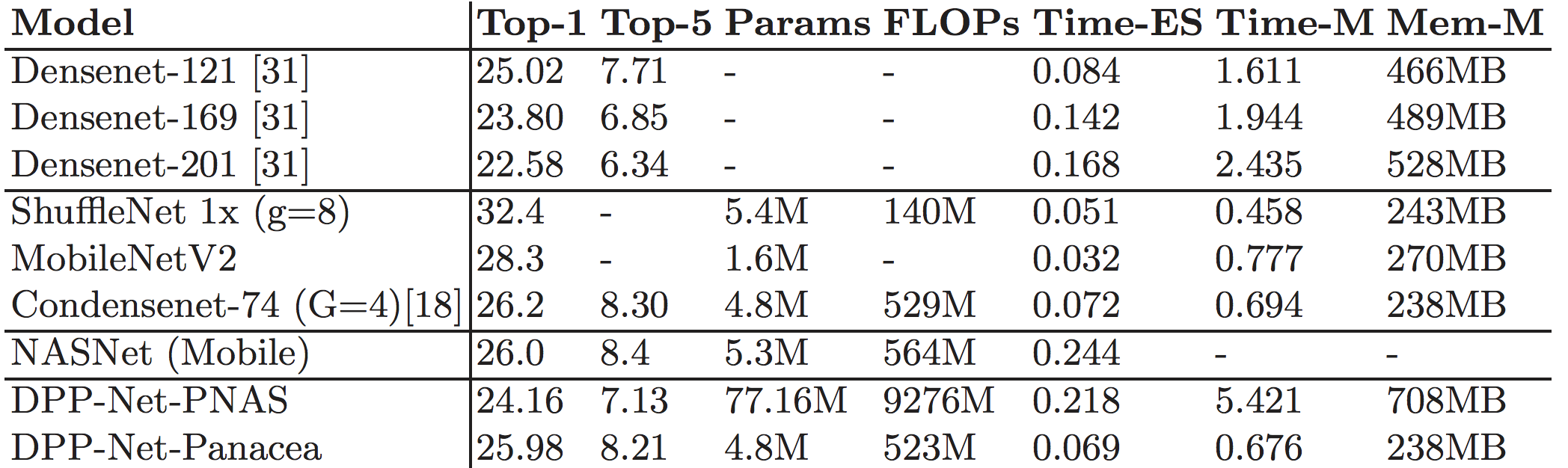
Table 2. ImageNet Classification Results. Time-M and Mem-M is the inference time and memory usage of the corresponding model on our mobile phone using ONNX and Caffe2. Due to operations not supported on this framework, we cannot measure the inference time and memory usage of NASNet (Mobile) on our mobile phone.
The observation that the best architectures on different devices are different inspires us to search for a distribution of architectures to handle various conditions. To the extreme, each data instance can best be handled by a different architecture. In [2], we study the instance-level variation, and demonstrate that instance-awareness is an important yet currently missing component of NAS (see Figure 1). We propose InstaNAS for searching for instance-level architectures; the controller is trained to search and form a “distribution of architectures” instead of a single final architecture. Then during the inference phase, the controller selects an architecture from the distribution, tailored for each unseen image to achieve both high accuracy and short latency. The experimental results show that InstaNAS reduces inference latency without compromising classification accuracy. On average, InstaNAS achieves 48.9% latency reduction on CIFAR-10 and 40.2% latency reduction on CIFAR-100 with respect to MobileNetV2 architecture.
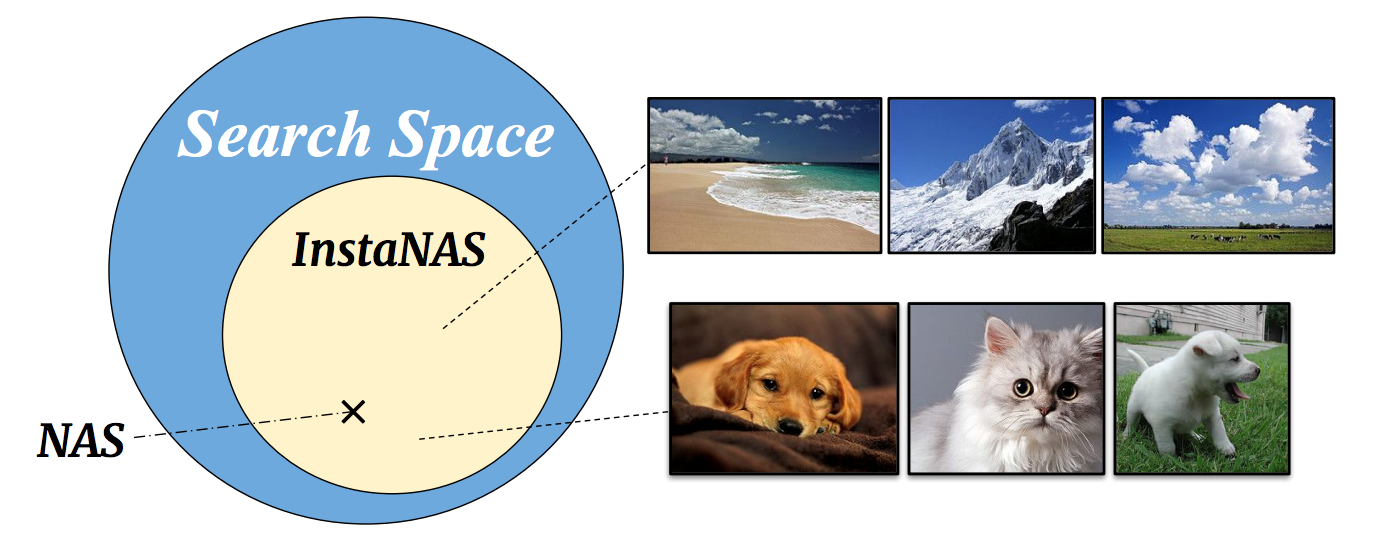
Figure 1. The concept of InstaNAS is to search for distribution of architectures. The controller is responsible for selecting a corresponding child architecture for each given input image. Each child architecture within the final distribution may be an expert of specific domains or speedy inference. In contrast, a conventional NAS method only searches for a single architecture from the search space as the final result.
In summary, we highlight two important NAS works. One is the first to optimize for multiple objectives including accuracy, inference time, and model size. The other is the first to search for distribution of architectures which enables instance-awareness for exploring a better trade-off between inference time and accuracy. We believe this line of work opens the door for more following works to leverage AI to design AI in the future.
References
[1] An-Chieh Cheng, Jin-Dong Dong, Chi-Hung Hsu, Shu-Huan Chang, Min Sun, Shih-Chieh Chang, Jia-Yu Pan, Yu-Ting Chen, Wei Wei, Da-Cheng Juan. “Searching Toward Pareto-optimal Device-aware Neural Architectures.” ICCAD, 2018.
[2] An-Chieh Cheng*, Chieh Hubert Lin*, Da-Cheng Juan, Wei Wei, and Min Sun. InstaNAS: Instance-aware Neural Architecture Search. Arxiv, 2019
RELATED


STAY CONNECTED. SUBSCRIBE TO OUR NEWSLETTER.
Add your information below to receive daily updates.