

The Age of the IoT and Networked Society: Major Industrial, Behavioral and Legal Issues Facing Taiwan

Author(s)
Tao-Hsing Chang & Yao-Ting SungBiography
Tao-Hsing Chang received his Ph.D. in Computer Science at National Chiao Tung University in 2007. From 1999 to 2008, he was a research fellow with the Research Center for Psychological and Educational Testing at National Taiwan Normal University. He joined National Kaohsiung University of Science and Technology in 2008 and is currently an associate professor in the Department of Computer Science and Information Engineering. His research interests center around artificial intelligence, natural language processing, text mining, and educational technology.
Yao-Ting Sung is a chair professor in the Department of Educational Psychology and Counseling at National Taiwan Normal University. He has received several awards for excellence in academic achievement, including the Da-Yu Wu Memorial Award and three Outstanding Research Awards issued by the Ministry of Science and Technology. His research focuses on educational psychology, psychological and educational assessment, computer-assisted learning and testing, as well as Chinese text analysis. Prof. Sung directs a world-leading team that specializes in bringing cutting-edge academic research and tools to improve automated affective assessment, readability measurement, and essay scoring. The team has built several diagnostic and assessment platforms based on the aforementioned technologies for career interest assessment, Chinese language learning, and adaptive reading.
Academy/University/Organization
National Kaohsiung University of Science and Technology, National Taiwan Normal University-
TAGS
-
Share this article
You are free to share this article under the Attribution 4.0 International license
- HUMANITIES & SOCIAL SCIENCES
- Text & Image
- November 22,2019
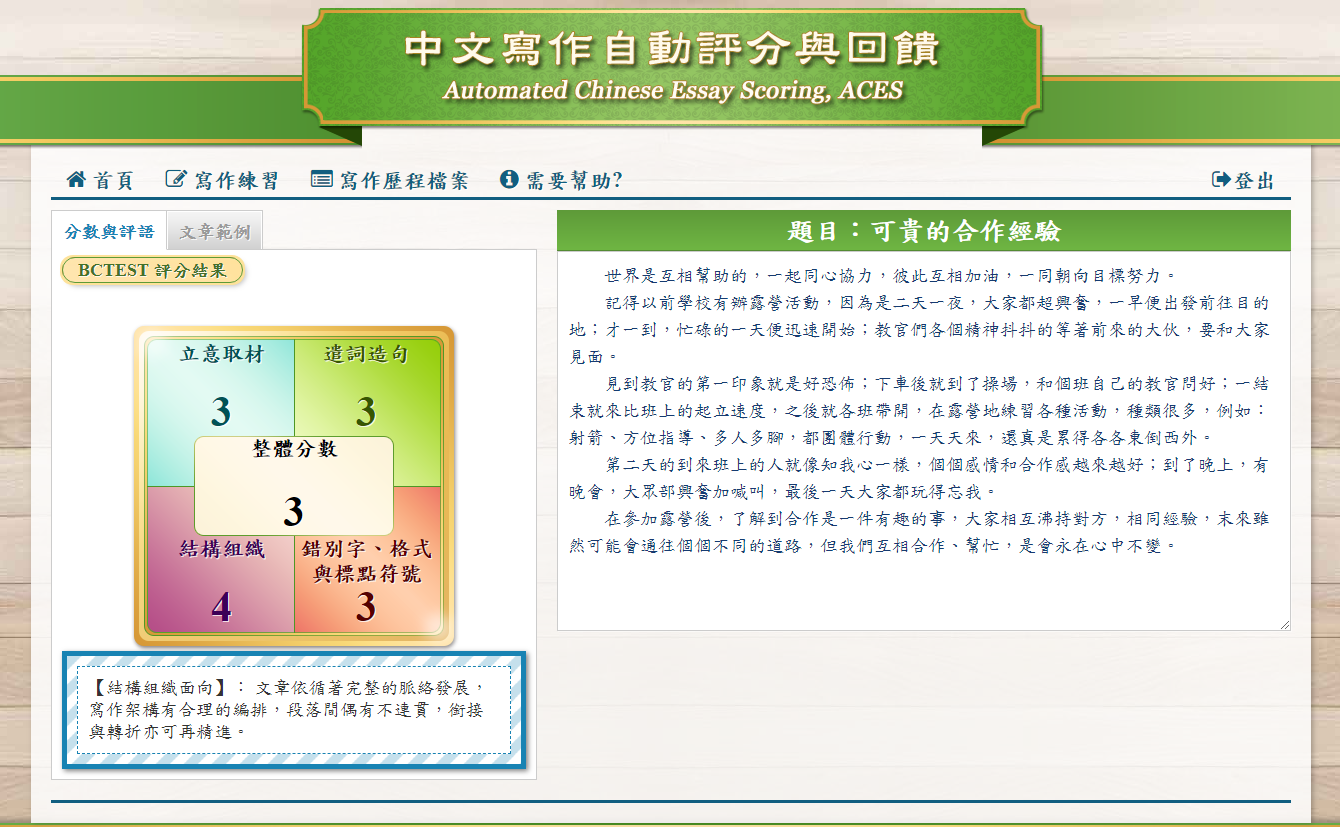
Writing assessment makes up an important part of the learning process as one masters the important linguistic skill of writing. However, this process has not been implemented effectively or on a large scale because the task of essay scoring is very time-consuming. The solution to this problem is automatic essay scoring (AES), in which machines are used to automatically score essays. The application of AES to English writing has been shown to be very successful. Due to linguistic differences, a redesign is needed before AES can be applied to Chinese. The purpose of this article is to introduce ACES, an automated system for scoring Chinese essays, by describing its basic framework, design principles, and scoring accuracy. Unlike some end-to-end AES systems, ACES’ basic framework is designed to provide more interpretative features. The experimental results show that the performance of ACES is stable and reliable, and on a par with other commercial English systems.
Teaching students to write is an important part of literacy education. A key component of writing education is the proper assessment of writing performance. Reading and gauging word by word, traditional writing assessment takes teachers (or raters) a tremendous amount of time and energy, posing a great obstacle for writing education. Such an obstacle makes school teachers keep the number of writing assignments within a manageable range, but the intensity of these exercises may not be enough for students. Additionally, large-scale standardized tests tend to adopt the relatively ineffective multiple-choice assessments, despite the widespread acknowledgement of the many advantages of constructed-response assessments such as essay questions.
Recently, automated essay scoring (AES) techniques have been developed. Most notably the application of e-rater by the Educational Testing Service to English writing assessment has been shown to be very successful. This article introduces an automated system for scoring Chinese essays (ACES) by describing its four modules, scoring accuracy, and future challenges.
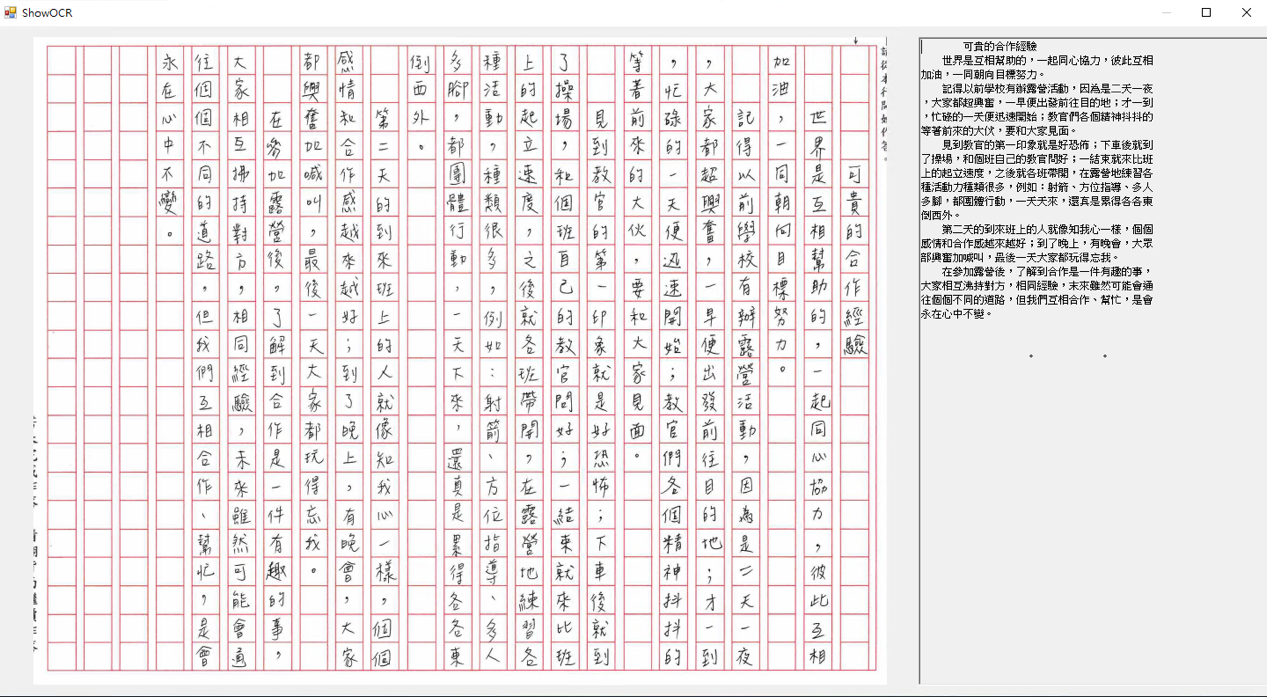
The optical character recognition module
Whether in a large-scale test or a teaching site, currently students' essays are mostly written by hand. Automated scoring systems must convert the handwritten text from a scanned document into machine-encoded text, hence the name “optical character recognition” (OCR). Our Chinese OCR technique is based on the convolutional neural network algorithm. The technique features the semantic analysis performed on the likely candidates of a character image whose probabilities are recalculated by the correlation with the preceding and succeeding characters.
The preprocessing module
In English sentences, every two words are separated by a space. Since there are no spaces between words in Chinese sentences, we developed a Chinese word segmentation tool called WECAn, utilizing both the maximum matching model and the conditional random field model. Moreover, WECAn employs an improved hidden Markov model to tag the part-of-speech (POS) of words. We also built a tool called HanParser to analyze sentence structure.
The feature extraction module
Writing abilities can be realized by four textual features regarding topics, rhetoric, organization, and misspelling.
Topics-This feature captures the fact that topical compositions describe more specific things addressed at a specified domain than those that depart from the prescribed themes. ACES extracts the related semantic categories using the semantic database of HowNet, and determines the topicality of an essay by computing the occurrence probability of each semantic category.
Rhetoric-By using NLP techniques such as the word2vec model, ACES identifies specified figures of speech and designs a detection module for determining whether these figures of speech appear in a composition. The different degrees and types of rhetorical features in a composition represent different levels of writing skills.
Organization-ACES uses a training corpus to establish a term co-occurrence matrix, which is employed to determine the dependency relationships of any two concepts. The major concepts in a composition are converted into a directed graph according to the order of their appearance and correlations. The organizational score is computed by discerning various degrees of similarity between the graphs of an individual essay and the leveled essays in the training corpus.
Misspelling-ACES uses a HanChecker tool to detect misspelt words in writing. Essays with more misspelling will have lower scores. HanChecker has four indices to determine whether a questionable character set should be replaced by a candidate word. These four indices are the character’s phonetic similarity, visual similarity, frequency ratio, and probability ratio for POS.
The scoring module
We designed a scoring module using the multivariate Bernoulli model (MBM). This scoring module can combine the probability of each score for different features of an essay. This final module assigns to each essay a machine-predicted score.
ACES was evaluated using both manually typed and OCR converted essays. A total of 4,800 essays from Taiwan’s Comprehensive Assessment Program for Junior High School Students in 2010, 2011, 2012, and 2014 were first manually typed and then automatically scored by ACES in a 10-fold cross validation taking experts’ scores as the criteria. The average exact precision rate was 0.597. In real-life essay scoring, it is acceptable for raters to vary by one score. Therefore, we also calculated the adjacent precision rate, allowing plus/minus one level prediction error. The resultant precision rate was 0.975. Using our OCR technique, we converted 660,000+ essays from the same examinations to electronic texts, on the basis of which the model of ACES was retrained and reevaluated. The adjacent precision rate was 0.986. This accuracy rate was identical to that performed on manually typed essays.
In the future, we aim to resolve two major challenges. First, the current system requires a sufficient amount of readily-scored essays as the training dataset. Second, essays that express unique viewpoints may be underscored by the system. To reach our goal, we will further investigate the relationship and mutual influence of approximate and intrinsic textual characteristics.
RELATED


STAY CONNECTED. SUBSCRIBE TO OUR NEWSLETTER.
Add your information below to receive daily updates.